Don't Squander the Lead
Anthropic built an effort toggle for Opus 4.7. Then withheld it from paying consumer users. A note from a shareholder who wants them to win.
Full disclosure upfront, same as always: I'm a shareholder in Anthropic. I built Force Multiplier AI on top of Claude and I use it every day. I want this company to win. This is the note you give a company when you are rooting for them and you see them doing a small dumb thing that will cost them more than they think.
I lost about four hours earlier this week on a DOS post.
Not to writer's block. To Opus 4.7.
I asked the model to help me draft a blog post covering three news beats regular readers of this site already know — the Venezuela operation in January, the Pentagon standoff in February, and last Friday's Mythos/Glasswing move — wrapped around a perspective I've shared that companies are in many ways the manifestations of their leadership. The assignment plays to its strengths: factual grounding, voice-matching, editorial judgment. I have drafted most of this year's DOS posts with Claude in the loop.
The drafts came back surface-level. The model missed the freshest fact of the week — the NSA running Mythos inside the same Department of Defense that has Anthropic on a supply-chain risk blacklist, broken by Axios on April 19. It wrote in abstractions when the piece wanted specifics. It responded to corrections with surgical word cuts when the piece needed a structural rethink. Three passes. Each progressively worse.
On the fourth attempt I handed the same prompt to Opus 4.6 with extended thinking turned on. The earlier version produced a near-publishable draft on the first try, with named side-deals, real dollar figures, direct quotes, a beat/counter-beat structure, and a payoff that tied back to a prior DOS post. Not in the same editorial weight class as what I had just spent four hours trying to extract from 4.7.
And then, proving the universe has a sense of humor, I used 4.7 to draft this post — the one you're reading now, about the 4.7 regression — and told it to think deeply, review a minimum of ten sources, and verify every factual claim to ground truth. It came back with Anthropic's effort tiers listed as "standard, high, xhigh." There is no "standard" tier on Anthropic's API. That's a GPT-5 tier name. It listed GPT-5's thinking levels as "Light, Standard, and Heavy," missing the fourth level entirely. It attributed a Hex customer testimonial as "Anthropic's own announcement language." It placed a $30 billion revenue milestone a month earlier than the reporting supports.
So: the model I was using to write a fact-grounded case about its own regression hallucinated facts about its own product in a post about its own accuracy. I caught it because I fact-checked the draft against primary sources. The four hours I lost yesterday happened because I didn't catch the quality drop fast enough.
That is not a one-off. A Reddit post titled *"Opus 4.7 is not an upgrade but a serious regression"* has thousands of upvotes across r/Anthropic and r/ClaudeAI. A similar post on X passed 14,000 likes. Roughly 85% of the top responses in the days after launch described 4.7 as a step backward from the prior generation. Issue #49244 on the official claude-code GitHub repo documents the pattern. The quote I have not been able to get out of my head, from a developer describing the new default: *"Instead of working with Claude I find myself arguing more and more."*
This is a product problem. It is a product problem worth writing about because it has a fix — a fix Anthropic has already built.
The mechanism has a name
Claude Opus 4.7 shipped on April 16, 2026 with a feature called adaptive thinking — now the only supported thinking mode, replacing the fixed thinking budgets available on earlier models. Instead of reasoning at a depth the user controls, the model estimates task complexity on its own and allocates reasoning accordingly.
Anthropic's announcement positioned this as an efficiency gain, and for coding it clearly is — 4.7 genuinely improved by about 13% on Anthropic's 93-task coding benchmark. But tucked inside a customer testimonial from Hex's CTO, quoted approvingly in the launch blog, was a sentence that tells the other half of the story: *"low-effort Opus 4.7 is roughly equivalent to medium-effort Opus 4.6."*
That was meant as a compliment about efficiency. It is also a description of what happened to the baseline. The default amount of thinking the model applies to an average consumer request came down. On coding benchmarks, the tradeoff is defensible. On open-ended editorial work, research synthesis, and long-form reasoning, where the model needs to hold an argument together across a large factual landscape, the tradeoff shows up exactly as it did in my session yesterday, and in the Reddit posts, and in the GitHub issue.
Here is the part that matters.
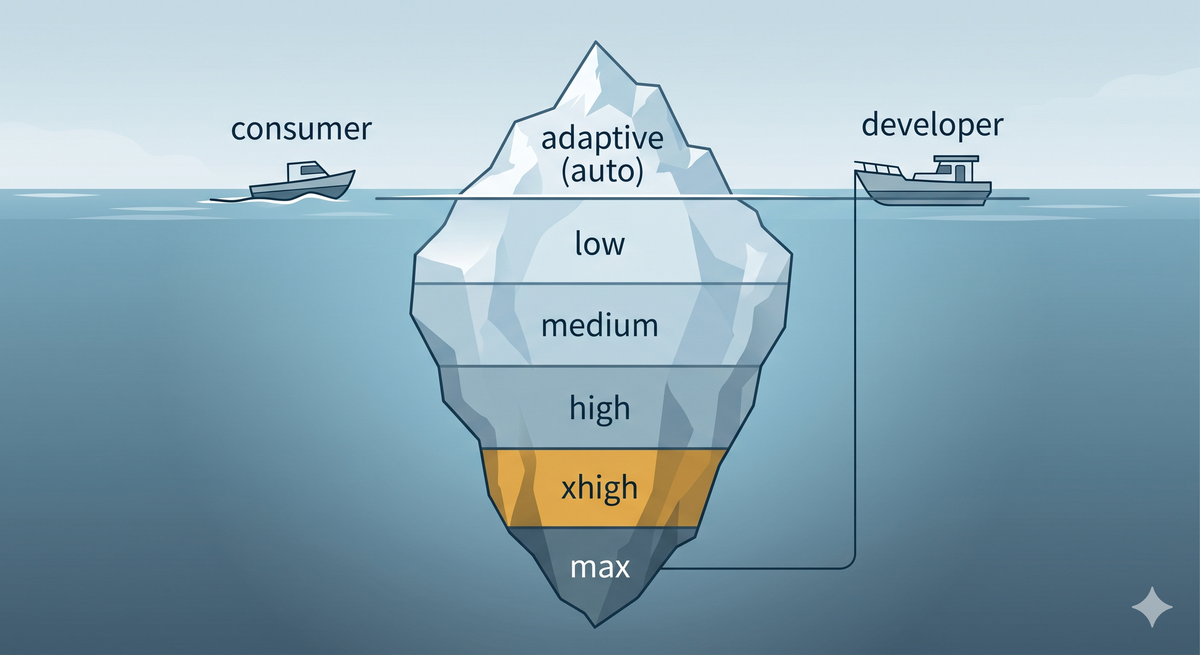
The control surface to solve this exists. On the API, Opus 4.7 exposes five explicit effort levels — low, medium, high, xhigh, and max — giving developers fine-grained control over how deeply the model reasons on any given request. In Claude Code, Anthropic set the default to xhigh — and users can toggle between levels with the /effort command. A developer calling the API or a coder in the terminal can pay for the reasoning depth their task demands and get exactly that.
A paying consumer on claude.ai, the desktop app, or Cowork — the person writing, researching, analyzing, making decisions about their business — gets whatever the adaptive heuristic decides, with no toggle to override it.
Anthropic built the control surface. They shipped it to developers and coders. They withheld it from the power users who write the largest individual checks and are most likely to notice when the reasoning gets shallow.
(note - our FxM i2 product was unaffected by all of this because we have these API switches available to us. This is just one of many reasons why a tool like this gives more control to businesses running AI as a mission-critical tool.)
The competitors already do this
OpenAI shipped a user-visible thinking-level toggle with GPT-5 in September 2025 — Light, Standard, Extended, and Heavy — available to Plus, Business, and Pro subscribers directly in the ChatGPT interface. Google Gemini 3.1 Pro shipped Low, Medium, and High thinking levels on February 19, 2026, configurable by both developers and users in AI Studio and the Gemini app.
This is now table-stakes for paying consumers of frontier AI. Anthropic built the same capability — arguably a more granular version of it, with five tiers — and declined to surface it in the products where it matters most for the people doing knowledge work, editorial work, and business analysis.
The math doesn't read as cost pressure
If I were writing the sympathetic version of this story — *"Anthropic had to tighten the consumer default because they are fighting for their life on compute"* — it would end here.
Anthropic is not fighting for its life.
On February 12, 2026, they closed a $30 billion Series G at a $380 billion post-money valuation. On April 6, Bloomberg reported that annualized revenue had surpassed $30 billion, up from $9 billion at the end of 2025 — passing OpenAI's roughly $24 billion run-rate for the first time. Bloomberg and TechCrunch reported on April 14 and 15 that unsolicited investor offers have arrived at valuations above $800 billion. Broadcom and Google announced a multi-gigawatt TPU partnership extending compute capacity into 2027.
This is not a company that needs to silently trim the reasoning budget on the consumer tier to keep the lights on. Whatever the 4.7 default is optimizing for — latency, inference capacity during a launch spike, protecting margins against competitive pricing — it is a tradeoff Anthropic is well-resourced enough to present as a user choice instead of a silent default.
The disposition argument cuts both ways
I've been writing for six weeks about Anthropic's disposition in moments of pressure. Venezuela in January. The Pentagon standoff in February. Mythos and Glasswing on Friday. The through-line in those posts has been: this is a company that does the expensive, values-aligned thing when the expensive thing is what is required — and that disposition is what you are buying when you pick them as a vendor.
The 4.7 consumer default is the opposite disposition on a smaller stage. A cost-and-efficiency move, rolled out without a user toggle, with no official Anthropic blog post addressing the regression reports, and a Claude Code team lead telling users on social to *"adjust your workflow"* rather than engaging the substance.
I am not equating the two. Mythos is a societal-stakes decision about whether to ship a cyber-capable frontier model into open commercial hands. The 4.7 default is a product decision about a consumer tool. But both reveal how the company handles friction when friction is the price of doing the right thing. And if I am writing posts arguing that Anthropic's disposition is the thing customers should trust, the small-stakes inconsistency is exactly the kind of crack that lets readers, fairly, ask whether the pattern is as clean as it appears.
On the big stuff, it still is. The 4.7 default is the small stuff, but it still matters — and the small stuff is where you show people what you do when no one is watching.
Right now, people are watching.
What good looks like
Ship the effort toggle on claude.ai, the desktop app, and Cowork. Call it what it is. Let paying users pick a reasoning tier — the same low through max that developers get on the API and coders get in Claude Code. Charge appropriately. I am happy to pay more for high-effort reasoning on the tasks that need it, and I would bet the power users driving Anthropic's consumer growth will be too.
If there is a real compute constraint behind the silent default, say so. Meter it. Give Max users a guaranteed monthly budget of high-effort responses. Give Pro users a smaller one. Let people buy top-ups. Anthropic already ships this business model on the API — the work is to surface it in the consumer UI.
If adaptive thinking is the right default for most people most of the time, which is probably true, keep it as the default. Just make the ceiling reachable on a button. The problem here is not that 4.7 is a worse model than 4.6. The problem is that 4.7 can reason as deeply as 4.6 with extended thinking — on the very same product surface — and paying consumer users are denied the switch.
Someone inside Anthropic has almost certainly already drafted the blog post titled something close to *"Introducing effort levels for consumer Claude."* Ship it. These things matter to businesses that rely on this technology, not as an innovation toy, but doing real things in production.
What it costs to get this wrong
OpenAI's history is the playbook Anthropic should avoid. Summer 2023: users reported GPT-4 behaving worse on specific reasoning tasks. A Stanford study documented apparent regressions — accuracy on prime-number identification reportedly fell from 97.6% to 2.4% in three months; the methodology was later contested, but the perception damage was real. What was not contested was the silence. OpenAI offered no public explanation for the changes in real time, and the trust cost ran for years. Then came the GPT-4o sycophancy episode in 2024, quietly rolled back only after sustained public pressure. Then the GPT-4o "legacy toggle" migration, which demoted a model paying users had built workflows around — complaints about that are still live on the internet.
The lesson from all three is the same. When a paying user's experience gets materially worse between model versions and the company says nothing on the record, the damage is not the model change. The damage is the silence. OpenAI has been paying for that silence for three years and counting.
Anthropic has spent the last six weeks giving the market a clinic on what transparent, values-aligned decision-making looks like in frontier AI. The ceiling on how well that story plays over the next two years depends on the company showing the same disposition in the product calls that do not involve the White House.
The good news is that this one is still small enough to fix in a week.
Don't squander the lead. Ship the toggle.
Disclosure: I am a shareholder in Anthropic. I am also the founder of Force Multiplier AI, which uses Claude extensively, among other AI models. Nothing in this post is compensated. All opinions my own.
Sources:
Product / release notes: Introducing Claude Opus 4.7 (April 16, 2026); Introducing Claude Opus 4.6 (Feb 5, 2026); Anthropic, Adaptive thinking (API docs); Anthropic, Effort (API docs); Anthropic, Best practices for Opus 4.7 with Claude Code
Business context: Anthropic, 30B Series G at 380B post-money (Feb 12, 2026); Bloomberg, Anthropic run-rate tops $30B / Broadcom deal (April 6, 2026); Bloomberg, Anthropic attracting $800B-plus investor offers (April 14, 2026); TechCrunch, Anthropic shrugs off VC offers (April 15, 2026)
4.7 reception: Startup Fortune, Opus 4.7 drawing rare unanimous criticism; Axios, Anthropic releases Opus 4.7 / user backlash (April 16, 2026); claude-code issue #49244
Industry precedent: OpenAI Help, GPT-5 thinking levels (Sept 2025); Google, Gemini 3.1 Pro / Deep Think thinking levels (Feb 19, 2026); OpenAI, sycophancy in GPT-4o post-mortem
NSA/Mythos context (referenced in opening): Axios, NSA using Mythos despite Pentagon blacklist (April 19, 2026)
Previous DOS posts in this arc: "The AI That Refuses to Kill Just Ran the Best Mission in a Generation" (Feb 23); "Hegseth Is About to Make America's AI Worse to Prove a Point" (Feb 27); "Who Are You Going Into Business With?" (April 20).